BigTable
is a distributed structured storage system built on GFS; Hadoop’s HBase is a similar open source system that uses HDFS. A BigTable is essentially a sparse, distributed, persistent, multidimensional sorted ‘map.’1 Data in a
BigTable is accessed by a row key, column key and a timestamp. Each column can store arbitrary name–value pairs of the form column-family label, string. The set of possible column-families for a table is fixed when it is created whereas columns, i.e. labels within the column family, can be created dynamically at any time. Column families are stored close together in the distributed file system;
thus the BigTable model shares elements of column oriented databases.
Further, each Bigtable cell (row, column) can contain multiple versions of the data that are stored in decreasing timestamp order.
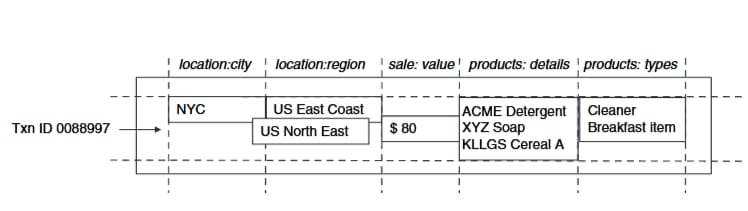
Figure 10.4 illustrates the BigTable data structure: Each row stores information about a specific sale transaction and the row key is a transaction identifier. The ‘location’ column family stores columns relating to where the sale occurred, whereas the ‘product’ column family stores the actual products sold and their classification. Note that there are two values for region having different timestamps, possibly because of a reorganization of sales regions. Notice also that in this example the data happens to be stored in a de-normalized fashion.
Figure 10.5 illustrates how BigTable tables are stored on a distributed file system such as GFS or HDFS. (In the discussion below we shall use BigTable terminology; equivalent HBase terms are as shown in Figure 10.5.) Each table is split into different row ranges, called tablets.
Each tablet is managed by a tablet server that stores each column family for the given row range in a separate distributed file, called an SSTable. Additionally, a single Metadata

table is managed by a meta-data server that is used to locate the tablets of any user table in response to a read or write request.
All client queries made through the Google Cloud Bigtable architecture are sent through a frontend server before being forwarded to a Google Cloud Bigtable node. The nodes are arranged into a Google Cloud Bigtable cluster, which is a container for the cluster and is part of a Google Cloud Bigtable instance.

A portion of the requests made to the cluster is handled by each node. The number of simultaneous requests that a cluster can handle can be increased by adding nodes. The cluster’s maximum throughput rises as more nodes are added. You can send various types of traffic to various clusters if replication is enabled by adding more clusters. Then you can fail over to another cluster if one cluster is unavailable. It’s important to note that data is never really saved in Google Cloud Bigtable nodes; rather, each node contains pointers to a collection of tablets that are kept on Colossus. Because the real data is not duplicated, rebalancing tablets from one node to another proceeds swiftly. When a Google Cloud Bigtable node fails, no data is lost; recovery from a node failure is quick since only metadata must be moved to the new node. Google Cloud Bigtable merely changes the pointers for each node
Leave a Reply